

by Alexandre Babeanu, 3Edges, and Tariq Shaikh, CapitalOne
Background
The true beginning of scientific activity consists rather in describing phenomena and then in proceeding to group, classify and correlate them.
Sigmund Freud
Identity and Access Management (IAM) systems have become critical in ensuring the security of enterprise applications. In the good old days of the on-premise / co-located data center, an enterprise could easily implement perimeter-based security – one where you would build a castle and a moat around your prized assets and then control the ingress & egress points to provide a reasonable security posture. The majority of access was granted to humans. Every human was given the appropriate level of access according to their job role, and everybody lived happily ever after… that is, until a dark cloud of disruption rained on the perimeter-based security parade. We are, of course, referring to the advent of cloud technology.
With a cloud-first approach, enterprises now have a significant portion of their prized enterprise assets and data deployed outside of their traditional data centers. Enterprises are shrinking their on-premise footprint and running workloads in the cloud. Identity, not network, is the new perimeter. One of the interesting aspects of this seismic shift was the rise of Infrastructure As Code (IAC) and, by extension, non-human accounts that manage the infrastructure. It is also not unusual to have cloud systems with thousands (if not tens of thousands) of permissions. This led to a proliferation of roles, and it became clear very quickly that the orthodox job role-based approach to access control needed adjusting.
Another unfortunate side effect of the identity-based perimeter approach was the rise of identity-based threats. A vast majority of breaches can be traced to compromised credentials and over-privileged accounts. It is becoming abundantly clear that an access control methodology that is dynamic and can evaluate access continuously based on risk signals in real-time is the need of the hour and a cornerstone of Zero Trust Architecture. Identity professionals responded to the challenge, and a variety of authorization and access control methods and corresponding ecosystems have developed. This is our attempt to enumerate these access control methods, categorize them, explore relationships between them, and, most importantly, provide guidance on how to choose your authorization system.
How to choose your next authorization system?
As highlighted in the preceding section, organizations need to shift their focus from old/legacy authorization models and systems to new ones capable of coping with today’s problems. This is not easily done when an organization’s whole infrastructure has evolved into its current state over a period of years or even decades… One therefore faces the two following questions right away:
- What authorization model or language to even choose to face these challenges?
We will answer these questions by first providing a Taxonomy of modern authorization models and then using it to provide some answers.
What is an Authorization Model?
Authorization systems are made of several complex components. Typically, an engine that makes access decisions, along with some other systems whose roles are to execute the decisions made by the engine or to fetch the data necessary for the engine to reach its decisions.
Our goal here is not to list all possible architectures of such systems or to describe them but rather to focus solely on the Policy Engine itself, which is at the core of the Policy Decision Point (PDP). Any PDP uses at least one methodology to compute its decisions. We call these methodologies for building PDPs “Authorization Models,” and the following sections describe a taxonomy of such Authorization Models.
What is a Taxonomy?
In simple terms, it is the science of naming and classifying things. To the authors’ knowledge, this hasn’t been done yet for authorization models, even though there is a great deal of confusion throughout the industry about the various ways authorization can be implemented. Each category in a Taxonomy may have subcategories, but it is important to note that the things being classified may belong to several categories at the same time. Objects can therefore be duplicated under several branches of the Taxonomy Tree if it makes sense (for example, consider a taxonomy of fish: salmon would be present under both the “Ocean” and “River” categories…).
A Taxonomy of Authorization Models
The first question when creating a taxonomy is to choose the right categories. This may be a contentious subject, especially in the field of authorization, given the enthusiasm of the Authorization community (the #Authorati) and the fact that there could be many ways to go about it. In the end, we opted for a set of categories that met the two following criteria:
- The categories, and the Taxonomy in general, should be helpful to all and not just serve a small community of specialists. In particular, it should help any Identity practitioner in making implementation decisions based on real-world criteria.
- It should cover all the existing models by avoiding duplicates as much as possible, as well as be easily expandable to any new, not yet invented models.
Figure 1 below depicts our proposed Taxonomy of authorization methodologies.
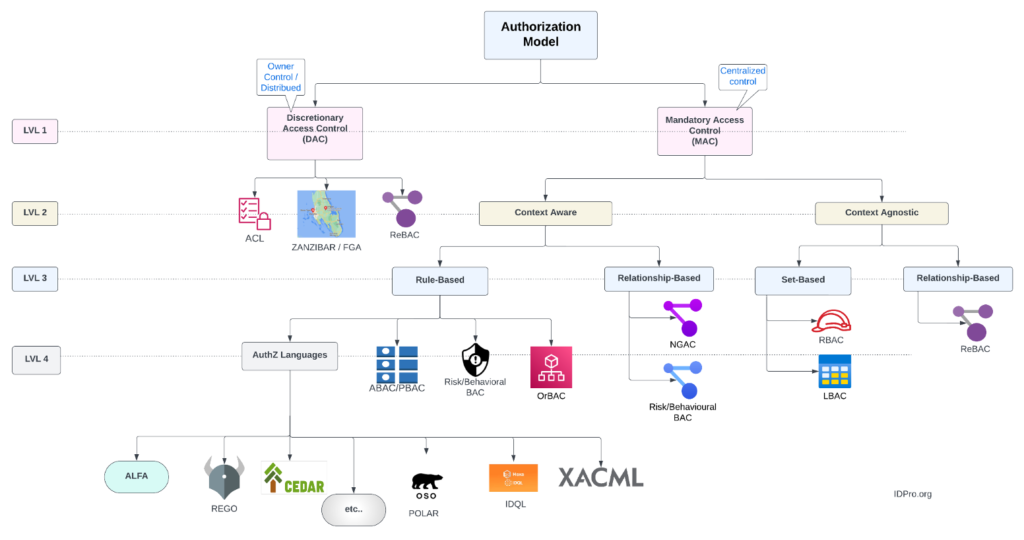
Figure 1 – A Taxonomy of Authorization Models
Level 1 – Centralized vs decentralized control
All models described here involve some kind of rules, even the simplest of them. The first categorization is to distinguish between those models owned and maintained by the owners of the Resources being protected (DAC branch) or whether these rules need to be centralized and administered by specialized administrators in a central location – see the Mandatory Access Control (MAC) branch. We find here our first authorization models
DAC branch:
- ACL: Access Control Lists, the oldest of all and the first model introduced through the Multics OS in 1969. Here, a resource owner maintains a list of all the subjects allowed to access any given resource they own, along with the type of access granted (typically read, write, or delete). Popular in operating systems such as Unix or in LDAP Directories.
- FGA/Zanzibar: Fine-Grained Access Control (FGA) solutions are all inspired by, or implementations of, the Google Zanzibar paper published in 2019. The paper describes Google’s own authorization model used throughout its various tools and offerings. Like ACLs, FGA solutions require resource owners to maintain “tuples” (text strings, essentially) that describe the type of access any subject may have to their resources. Because of the considerable amount of tuples potentially required by such a system, they are best suited for DAC applications (which is also Google’s use case).
- ReBAC: Relationship-Based Access Control (ReBAC) is an approach that uses the paths between subject and resource nodes in a data graph in order to determine access. Access is granted if such paths exist. ReBAC uses native graphs and requires a proper Graph Database store (more on this further). Note that ReBAC can be used for both DAC or Mandatory Access Control (MAC) applications.
🛑 Note: We make a distinction here between FGA systems and ReBAC: we view these as different models altogether. Although FGA tuples describe a graph, those tuples are not stored in graph databases but are rather strings stored in SQL or custom databases. On the other hand, ReBAC systems use graph databases and express policies as Graphs, not as programming languages. This means that path traversals and tooling are vastly different between those systems. A Graph-based ReBAC policy is therefore an image/diagram and not a block of code, as is the case for FGA systems.
Level 2 – MAC Models
Centralized access policy models are of two kinds: those that can be context-aware and can implement environmental or other contextual conditions and those that are ignorant of context. The contextual conditions can be based on date and time, locations, or even specific attribute values.
Level 3 – Context-Aware models
At this level, and on the context-aware branch, we find two subcategories. Here, the authorization models can be based on rule sets or instead use relationships between entities in order to compute access. Relationship-based systems are graph systems.
Graph Approach
Graphs can implement two types of context-aware models:
- Next Generation Access Control (NGAC), which is an ANSI Standard (* See: https://webstore.ansi.org/standards/incits/incits4992018 ). Look for NGAC-compliant systems that provide no-code / low-code interfaces.
- Risk and Behaviour-Based Access Control (BeBAC): a model by which subjects’ behavior is tracked as a graph, and baselines established for acceptable behavior. These systems can then apply graph pattern-matching or graph analytics techniques to find outliers and thus compute the risk of any given access request.
Another common technique here is to compute the risk score of a given user/entity (similar to a ‘FICO score’) and calibrate ‘access credit’ based on the user/entity risk score, the nature of the request (e.g., privileged v/s nonprivileged) and the type of object/resource that is being accessed. For instance, a user/entity may be denied privileged access to a resource (such as a high-risk PCI database) if their risk score passes a certain threshold (the equivalent of an ‘Excellent’ FICO score due to recent activity that falls outside of the established behavioral norms for the user/entity).
Rule-Based Approach
The non-graph approach is more traditional and, in the case of some vendors, has been available since the beginnings of ABAC and the XACML standard. In this approach, the access policies are defined by a set of programmatic rules, defined either using modern authorization languages or through solutions that provide more business-friendly front ends. The rules combine Subject and Resource attributes with environmental conditions in order to compute a logical decision.
At this level, we find:
- Authorization languages: Any specialized language that can express access policies using attributes and their values. We find some standardized languages (XACML, ALFA) and as well as some vendor-specific ones (the others). These languages let developers typically implement their own flavor of ABAC/PBAC (see below).
- ABAC / PBAC: Attribute/Policy-Based Access control systems. These systems implement ABAC without a language per se; they rather rely on tooling and/or GUI widgets to help or guide users during the creation of the policies. Note that the authors believe ABAC and PBAC are synonymous in that all ABAC systems also need to define and manage policies.
- Risk and Behaviour-Based Access Control (see definition above).
- Organization-Based Access Control (OrBAC): A model driven by the subject’s and Resource’s membership to an organization. This can be based on business units within a company or even on different organizations altogether. OrBAC uses dynamic rules and context, as well as a hierarchy of Organization, Role, Activity, and View in order to determine access to its resources.
Level 3 – Context Agnostic Models
On this side of the tree, the authorization models don’t support the use of any environmental conditions. These are easier models to use and understand, but they are also much more limited. The two sub-branches here refer to the way to group Subjects and the Resources they try to access.
On the Set-based branch, subjects and resources are grouped together by some common factors, such as users sharing the same semantic role, security level or organization. The other side is, again, relationship-based and uses graphs to determine access.
Note that the set-based approaches are all prone to rule “explosions”: over time, the number of sets increases to the point where it eventually becomes very difficult to certify with certainty the access of subjects to all resources.
Set-Based Models
We find here:
- Role-Based Access Control (RBAC): in use since its creation in 1992 by NIST researchers, this is still to this day the most popular (by far) Access Control model. Users are placed in roles; each role is granted a set of entitlements over resources.
- Lattice-Based Access Control (LBAC): Uses the mathematical concept of lattices to define the levels of security a subject may have and may be granted access to. The Subject can thus only access any given Resource if their security level is greater than or equal to that of the protected resource.
Relationship-Based Models
Here we find only ReBAC, which can also be used with centralized control. Generalizing in a graph is easily done by just adding intermediary nodes. Adding extra hops can make ReBAC less fine-grained and, hence, easier to handle and manage.
How to choose?
Figure 2 below represents a decision tree that can be used to help choose the right model. Simply answer some basic questions to follow a path in the tree to a leaf node.
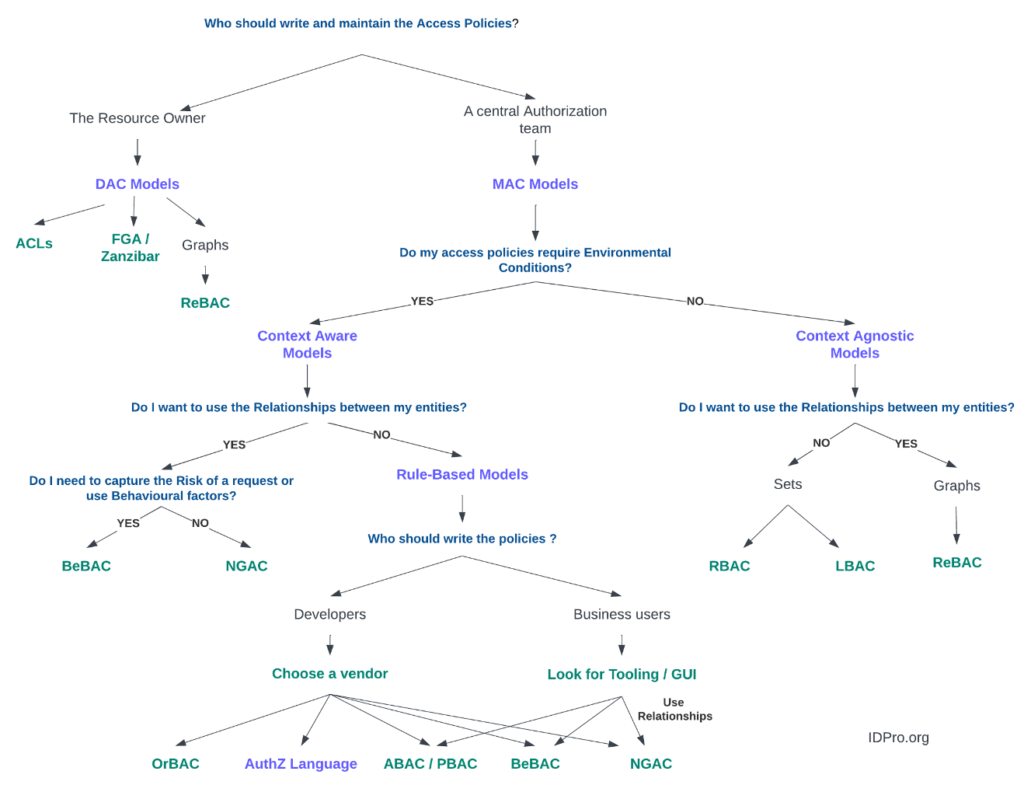
Figure 2 – An Authorization Decision Tree
Conclusion
This publication is the authors’ attempt to provide a first cut of a taxonomy model for authorization. Without taxonomy, we’re explorers without a map, scientists without a method. It brings order to chaos and meaning to complexity. As the saying goes, all models are wrong, but some are useful; we hope that readers will find the taxonomy model useful in disambiguating some commonly used terms, putting them in context, and simplifying complexity. We fully expect the taxonomy and the decision tree to evolve over time to meet the needs of the changing technology, threat, and business landscape. The accompanying decision tree can be a very useful tool in the Identity professional’s toolkit to aid in the selection of an authorization model that is appropriate for the business case. So the next time you are wondering which authorization model to select for your application, go ahead and use the taxonomy and the accompanying decision tree to guide your selection.
Authors
Alex Babeanu
Alex leads the research and development of 3Edges, which created the best and easiest to use Graph platform on the market, specifically built for graph-aware dynamic authorization. His past experience includes building pieces of the Oracle Identity Manager server as a Principal at Oracle, and over 10 years spent as a consultant in the field, architecting many solutions for public and private organizations in all verticals. Alex holds an MSc in Knowledge Based Systems from the University of Edinburgh, UK, and is an avid Sci-Fi enthusiast.





Tariq Shaikh
Tariq is an Identity Architect, Director & Distinguished Engineer at Capital One. He has 25 years of technology experience and a passion for developing innovative technology solutions to solve cybersecurity problems. Prior to Capital One, Tariq led the Cloud Identity & Access Management (IAM) and Privileged Access Management (PAM) initiatives at CVS Health. He started his career as a software developer before taking on cybersecurity leadership & advisory roles. He speaks and posts extensively about Identity & Access Management topics.


