

by Alex Babeanu, Identity Solutions Architect — Nulli
The Golden Age
We can trace the field of Identity and Access Management (IAM) back to the creation of the password by Fernando Corbato in 1961. We’ve had to manage user accounts ever since.
Because of these user accounts, two further inventions have shaped IAM since that milestone:
- The creation of Relational Algebra ( Edgar F Codd, “A Relational Model of Data for Large Shared Data Banks”, 1970). Which led to the creation of the first SQL-based Relational Database System, Oracle v.2 in 1979;
- The creation and eventual approval of the X.500 set of standards in 1988.
These 3 inventions are still ubiquitous—33 years after the creation of the last one. Nothing new has really happened since. We still store and manage Digital Identities in Directories and/or SQL databases, and we’ve done this since Epoch.
However, the challenges of the hyperconnected modern era have shown massive cracks in these old foundations…and some companies have started to notice (I have names).
The Problem with Modern Identity
Volume
We live in a very different world today than during that famed epoch. 4.6 billion users had access to the internet as of the end of 2020, 50% of all internet traffic now goes through mobile devices, there are close to 36 Billion installed/live IoT devices this year around the world, and that number keeps growing.
Figure 1 below best summarizes this trend: the total volume of data created worldwide since 2010 and projected up to 2024.
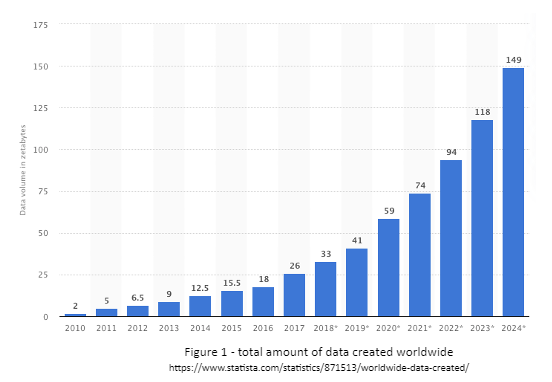
The thing to note is that before 2010, the total amount of data stored worldwide was negligible when compared to the amount in use today.
Complexity
But data volumes are not just humongous nowadays, data has also become exceedingly complex. For instance, the Observatory of Economic Complexity (OEC) publishes data visualizations of the complexity of worldwide economic exchanges. Figure 2 below represents an example of the data they make available:
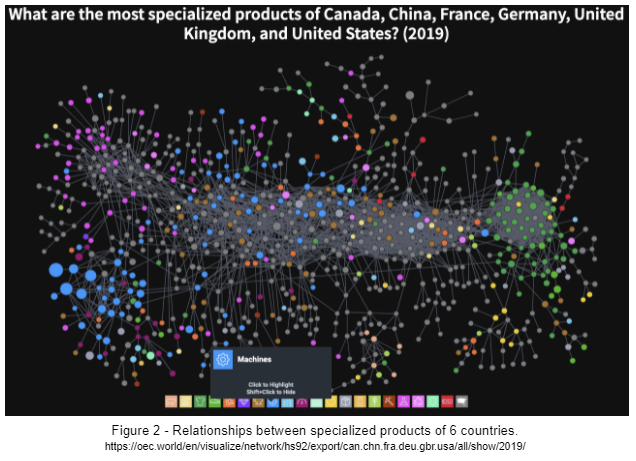
There is indeed a relationship between textiles fabricated in China and chemicals produced in Europe. Not a “1-hop” relationship mind-you—not at all. Instead, you have to follow certain paths of products and subproducts, of interconnected partnerships and data exchanges to get from one to the other. It’s not just 1-1 or 1-N relationships anymore. No, it’s more like 1-N-N-…-N-1 these days.
Complexity arises as soon as several actors interact and start exchanging data. Complexity increases further when one starts to ponder the ways in which to protect the access to all that shared information. A good case-in-point here is the new B2B2C business model. We currently lack a truly holistic view of all the actors and resources involved in such systems.
Graphs
At this point, we have to stop and ponder the reasons why Relational Databases and LDAP Directories have been, and still are, ubiquitous in IAM. The reason is simple: both can capture the relationships that link entities together—to some extent at least.
LDAP Directories can only represent hierarchies (parent/child relationships). This in itself is very limiting, as the only way to relate any 2 objects to each-other is to create a common parent. This quickly leads to an unmanageable explosion in the number of such parents as the number of arbitrary relationships increases—exactly the cause of the infamous RBAC Role Explosion.
At least SQL Databases support all kinds of relationships. Nevertheless, they can’t cope with the sheer number of relationships that must be modelled. As mentioned above, we now have to deal with many 1-N-N-…-N-1 relationships. And as we know, joining huge tables (remember the Billions of Identities we need to manage today?) together, or with themselves (the infamous “friends-of-friends” query), many times over can bring the most advanced SQL databases to their knees pretty fast.
Not so for Graph Databases!
Graphs are simple diagrams made of Nodes and Relationships (arrows) that can actually model any data at all.
Figure 3 below is a simple Identity Graph example that depicts the relationships between 2 Identities (a User and a Client) and a Company (“Walstuff”):
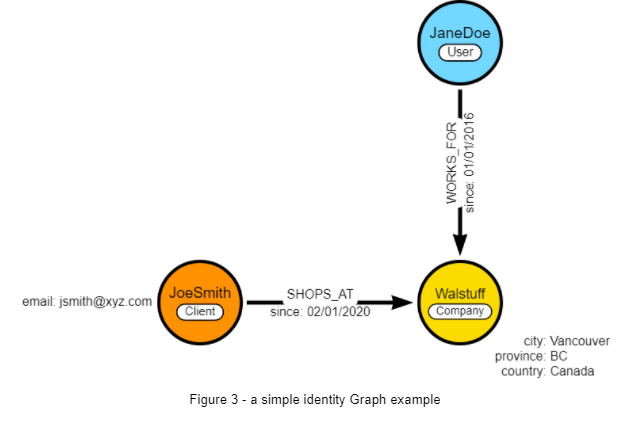
A great value-added of Graphs is that they are easily readable in plain natural language, and readable by pretty much anyone. For instance, just follow the arrows in the graph above to “read the data” in plain English.
Representing data as Graphs actually solves all the problems inherent to the legacy tools we’ve been using for so long.
In particular:
Multi-Joins
Querying a Graph for an Access request for example boils down to finding a path, or set of paths, between a subject identity and the resource it tries to access. A path in the graph has the same length no matter how many other billions of nodes are stored in the database. The time it takes to process a path query is the same, regardless of the amount of data in the graph. Compare this to SQL joins.
Data Complexity
This is better shown.
Figure 4 below is still a simple Graph. To the Graph of Figure 3 above, we’ve now added a B2B2C partner (“InstantShop”), as well as their flagship Web App “OnlineOrders” and only 1 of their users. The result is still readable in plain English—just follow the arrows.
Now the clients of our Walstuff supermarket can also buy their products online through their OnlineOrders app. Same products, same clients, different channel. Note that employees from both sides should be able to support this new system.
Who can access what in such a model?
Please note that this is just an example and doesn’t reflect any actual IAM system.
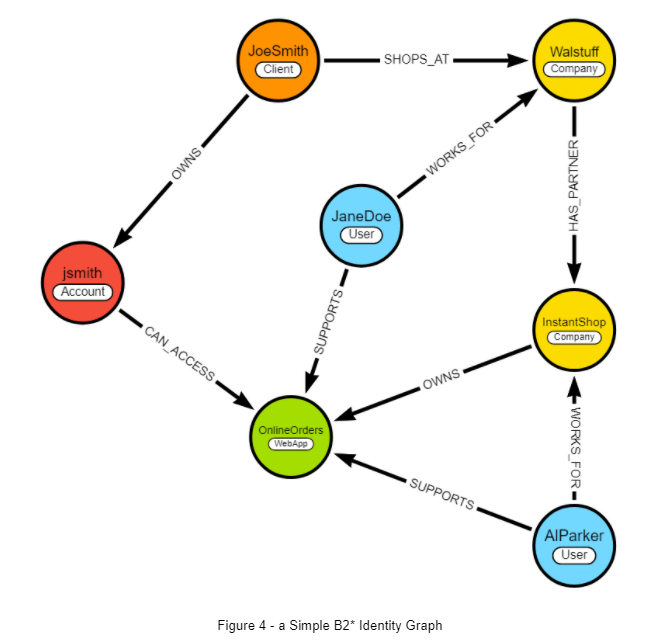
Ok, now try to model that in LDAP (and please email me if you find a good solution).
Conclusion
It is time for a paradigm shift in IAM. Given the challenges we face nowadays, we need data stores that can truly manage relationships, ones where relationships are true first class citizens, which can represent any arbitrary type of relationship. It is time to switch to Identity Relationship Management (IRM)!
In the fully distributed and Identity-centric world of tomorrow, full of Distributed Identities, Consents, and Verifiable Claims, the only real way to make sense of Identities and their Entitlements is to consider them along with their relationships, in context—their context graphs.

