

There are many ways to skin the high-availability cat using AWS’s Route53 DNS service. Here are some test results from my quest to get as close to instantaneous regional failover as possible.
I have spent the last couple weeks thinking on how fast I can get Route53 to failover from one region to another, and how narrow I can get the window of “page not found” type errors that a user was to see during the fail over time. I care about this because during the last couple of years I have architected, built, launched, and now run an SSO deployment that spans three regions. It is functionally an IDaaS service built on AWS and COTS identity software (PingFederate). Here is my presentation on that service at the 2019 Identiverse conference for more details.
The salient bits that involve Route53 and my desire to optimize failover stem from the following:
- Unlike some IDaaS providers, sessions are generated and respected by every node in the global cluster. Though the global super cluster is composed of regional subclusters in AMERS, EMEA, and ASPAC regions, all nodes respect all sessions generated by all the other nodes/subclusters.
- Each regional subcluster can validate state through consensus amongst nodes for certain read-only transactions. Thus, for the best user experience, we want to keep users routed to the regional cluster closest to them so those read-only transactions can be validated in the regional subcluster rather than having to wait for the global cluster to achieve consensus on the state.
- If a region is lost, the session state can be redistributed amongst the remaining nodes in the other regions. The user experience of that failover is what I am looking to fully understand with this test.
Test Setup
I setup apache servers in three regions, US-East-1, EU-West-1, and AP-Southeast-1, and configured them to show a simple homepage that displayed their region name.
I then placed each one behind a load balancer for ease of having a consistent DNS name to route to for my tests since I didn’t want to bother setting up VPCs and subnets with publicly accessible DNS names in three regions. I would use those DNS name in order to map a vanity url, sso.redbeardidentity.com, across various Route53 routing policies. This way, as I took each of the three nodes down, I could easily see which of the three nodes were serving the page.
I also built a simple bash script that would curl sso.redbeardidentity.com every 1 second, and grep and display the header. This gave me something that wouldn’t require me to refresh an incognito browser that I could use to observe failover. I then built out some Route53 policies and started turning apache servers off and on.
Health Checks, TTL, & ALBs v. NLBs
Out of the gate, there are a few very major items that can be tuned to improve failover performance without dipping into any Route53 architecture, mainly TTL and health check frequency. TTL (time to live) determines how long the DNS resolver is supposed to keep the DNS query cached before doing another one. By default, AWS Route53 record sets have a TTL of 300s, which are probably fine for most purposes. However, when you are staring at a stopwatch waiting for your script to flip from “US EAST 1” to “EU WEST 1”, those 300s feel like an eternity. In preliminary testing, the speed of failover correlated with a shortened TTL. For all my tests, I dialed the TTL down to 1s. To be honest, I am not certain the implications of this outside of every call to the service requiring a DNS lookup along the way- but since the goal is to make sure that things failover as fast as possible, and that the larger TTL values slowed those failovers, I concluded that the tradeoff was worth it.
The next major thing that will impact failover performance is the count and interval between each Route53 health check. These are found under the Advanced Configuration options when configuring a health check.

Leaving the failure thresholds and request intervals at their defaults guarantees at least 90s before any health check-based routing policy takes effect. For the tests below I dialed this down to a failure threshold of 1, and a fast 10s request interval.
Finally, and something that initially confounded my results after a few days worth of testing is the difference between Application Load Balancers and Network Load Balancers to failover performance. I’ll leave it to Amazon to explain the distinction, but the short answer is that ALBs operate at an application layer (layer 7 in the OSI model) and NLBs operate at the transport layer (layer 4). It turned out that setting up ALBs in front of the apaches measurably impacted failover performance compared to NLBs, so pick NLBs if performance is king.
So let’s start looking at what kind of policies we can play with in Route53 and how they compare.
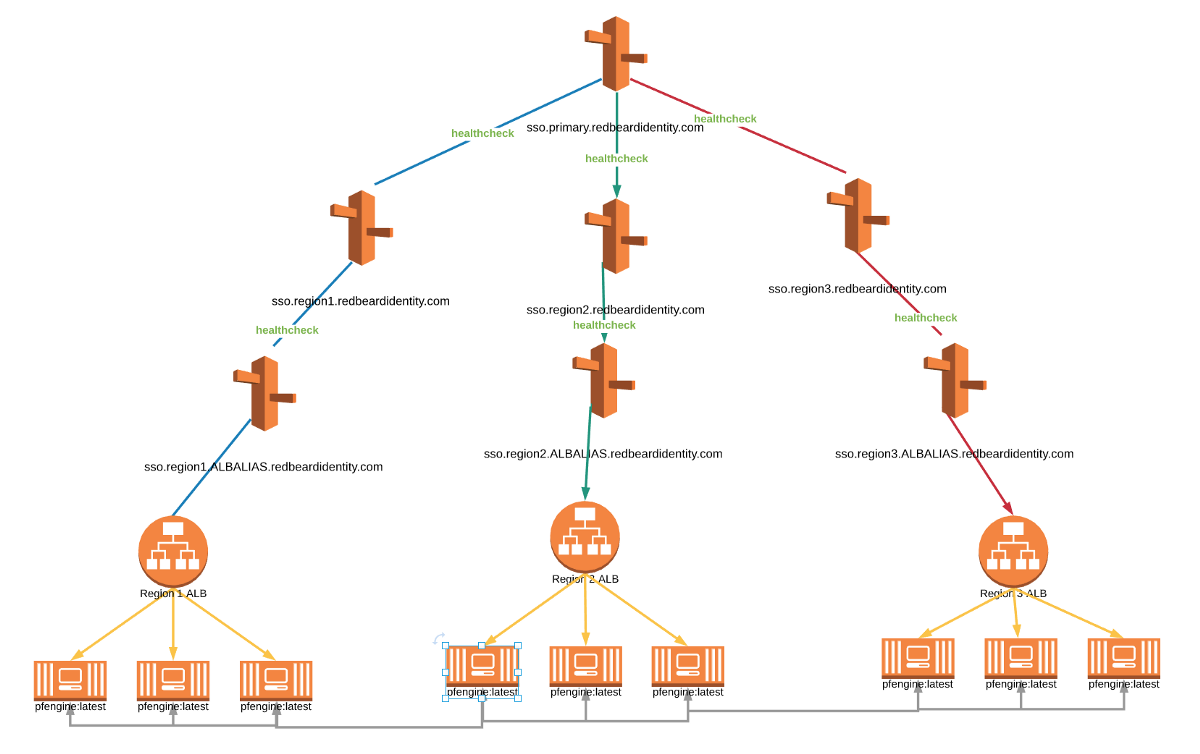
Latency Routing + Nested Failovers
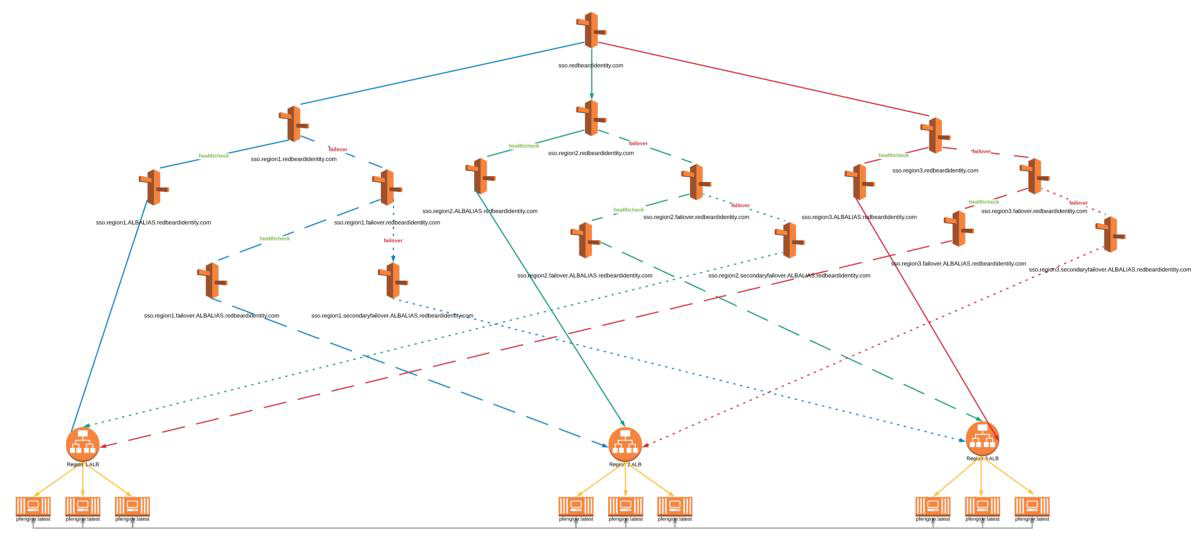
This design starts with latency routing to point the requestor to the region with the best performance for them, and after that uses a series of cascading primary/secondary failover policies to route the requestor to the endpoints. Each region’s primary route maps to the DNS of the ALB in front of that region’s cluster. The first failure routes to a second Route53 alias, which itself is then mapped to a second primary/secondary failover policy. That failover’s primary route maps to the DNS of a second region’s ALB, and its failure to the DNS of the third region’s ALB. As such, each region has hard-coded primary, secondary, and tertiary routes to hit the cluster, and some care must be taken that the secondary and tertiary routes make sense based on the regions used by your design. This could scale up to as many regions as needed, at the cost of a significant number of Route53 objects.
We can reuse the health checks at each ALB for decision points further up the routing policy since the decisions are ultimately based on the health of the targets behind those ALBs. Here we built the AMERS side of the routing tree and attached health checks to the Primary Failover routing aliases, as well as all three Latency aliases.

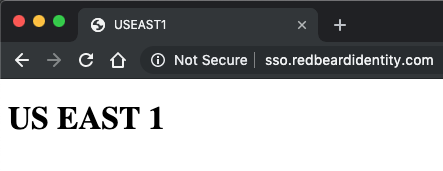
We fire up the testing script and start grepping. As expected we see sso.redbeardidentity.com getting served by US-East-1. Once we shut it off we see the expected “Bad Gateway” error as the ALB responds with no valid targets.
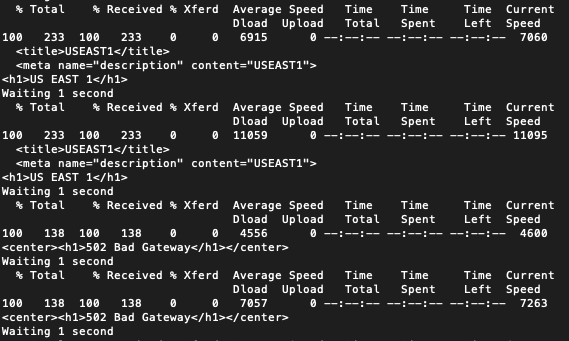
But then, “Bad Gateway” doesn’t switch to EU-West-1. Instead, we can no longer resolve sso.redbeardidentity.com at all.
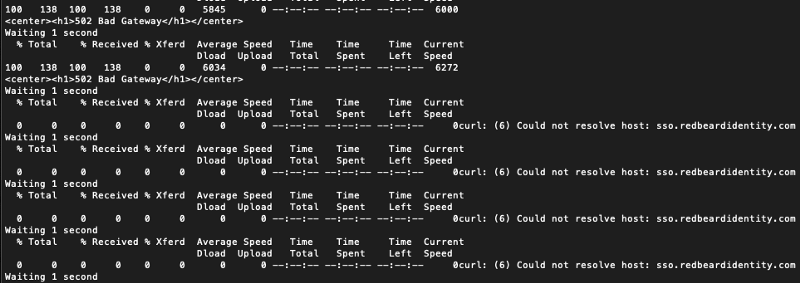
So what happened? Well, it worked exactly as we told it to. When using the failover design, applying health checks at the latency routing layer broke the additional routing policy applied beneath it- or that is to say, it made it entirely redundant. This makes sense since Route53 evaluates the health of the sso.redbeardidentity.com -> sso.amers.redbeardidentity.com leg, finds it unhealthy, and instead sends the traffic to the next best alias based on latency based on my point of origination- which looks like EU-West-1 from my mid-Atlantic origination point. Since I didn’t bother building the EMEA routing tree as part of this exercise, it didn’t switch to EU-West-1 once the latency layer switched to from sso.amers.redbeardidentity.com to sso.emea.redbeardidentity.com. Dropping the health checks at that layer allows the next leg down on the AMERS routing tree to be evaluated.

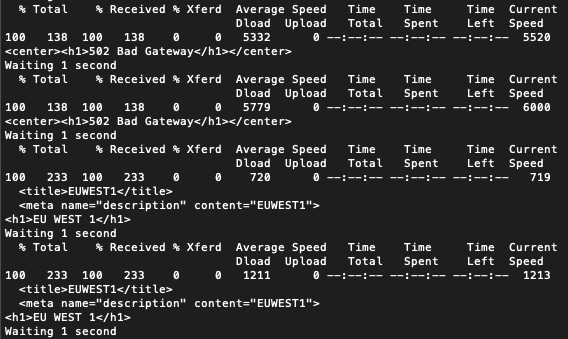
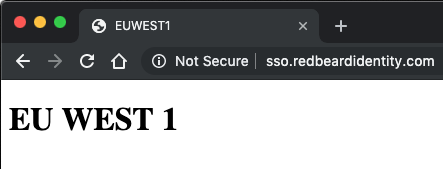
And if we kill httpd on EU-West-1, we failover to AP-Southeast-1.
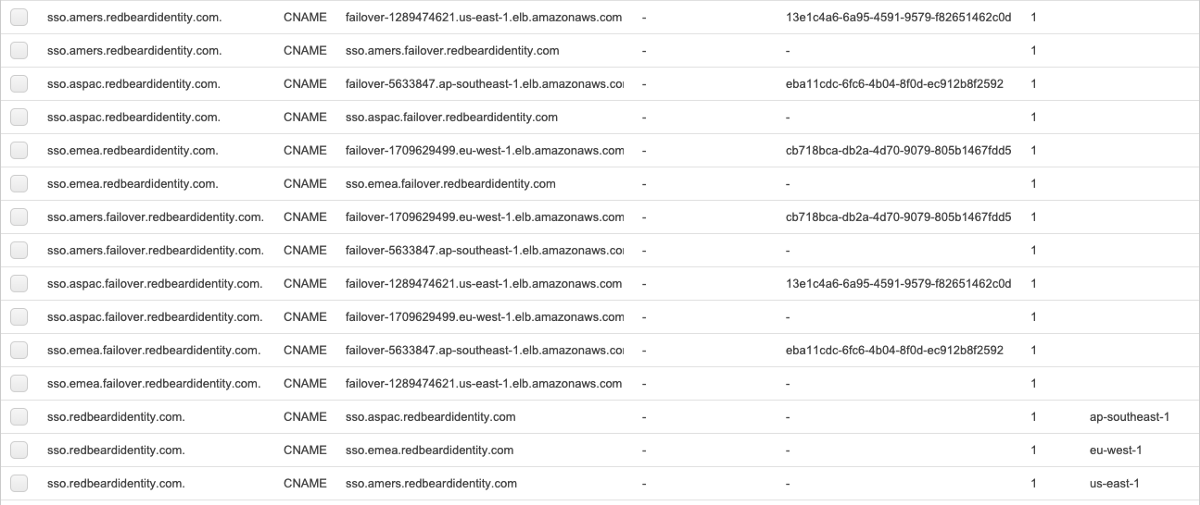
So let’s build out the rest of routing trees in EMEA and ASPAC regions and test our assumptions that the failovers will work as we expect. After mapping all the aliases, here is what I have in Route53:
I added a health check to the sso.redbeardidentity.com -> sso.amers.redbeardidentity.com latency routing layer to force me to fail to EMEA routing tree.
With US-East-1 down, I should show sso.redbeardidentity.com resolving to EU-West-1-
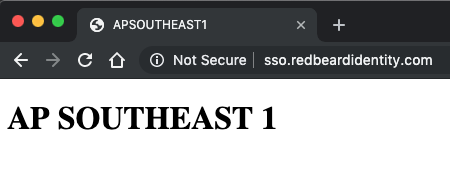
And then fail to AP-Southeast-1 when I shutdown EU-West-1.
Shutting down AP-Southeast-1 results in a failure to resolve sso.redbeardidentity.com as long as the US-East-1 latency health check keeps me in the EU-West-1 routing tree.
As nice as it is to predictably fail to a given region with the primary/secondary/tertiary routing available with this design, the variability of failover performance at the latency layer is a huge drawback. Under the best of conditions, with Network Load Balancers as the endpoints, failing from AMERS to EMEA took 25s, and EMEA to ASPAC 23s. Using ALBs, the failovers took 50s from AMERS to EMEA and 45s EMEA to ASPAC. However, the lack of health checks required to use this configuration means you are at the mercy of Route53’s next latency calculation. For every test that took seconds to failover, there was another that took minutes to do so, with some tests lasting over 10 minutes before failing over. That is a bit too much variability for me to consider this latency + nested failovers a serious contender for production design.
Latency Routing + Weighted Routing
What if we could accomplish the same outcome as the nested failovers using far fewer Route53 objects? Turns out weighted routing can do just that. This happens to be the configuration currently in use in the open-sourced branch of my AWS deployment of PingFederate.
In a traditional weighted routing configuration, you set weights for each alias, and the requests are sent proportionally to the weight given to each alias. This isn’t a percentage calculation. For example, if you had three nodes that you wanted to serve traffic behind sso.redbeardidentity.com, you would create three weighted record sets and map sso.redbeardidentity.com to each of their DNS names. If you assigned the first node a weight of 10, the second a weight of 100, and the third a weight of 33, it would mean that for 143 requests headed to sso.redbeardidentity.com (the total sum of all the weight values for the record sets), Route53 would route it so that first would handle 10/143, the second 100/143, and the third 33/143. This means we can assign an arbitrary weight to a recordset for our ALB and arrange that 100% of the traffic goes to that weighted alias. Place weighted policy behind a latency policy and Route53 will go back up to the latency routing tier to find the next available weighted policy capable of fulfilling the request- which means we have a much simpler method for multi-region failover.
For this, we are using Aliases to point the three regional latency routes to their corresponding regional weighted routes
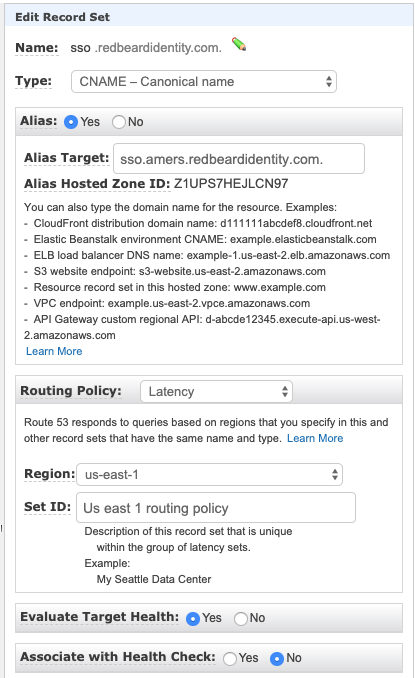
It will look like this when you are done.

So once again, we start hitting sso.redbeardidentity.com to see which node fulfills the request. We start with US-East-1. Given our 1s TTL and 10s/1-strike health check, hopefully, we should hop to EU-West-1 in about 15s assuming EU-West-1 remains the next best latency experience from my mid-Atlantic point of origination.

Fifty seconds for failover is respectable, but not what I was hoping for. In other tests, I have seen the failover vary between 30 seconds to five minutes when using the generic “evaluate target health” option on the latency policy, which I suspect has to do with the timing of the failover and Route53 re-evaluating its regional latency. Rather than deal with that variability, we can instead just apply the health checks we use on the weighted policies on the latency policies to make the failover timeframe more predictable.

This configuration got the time down to 30 seconds. I think it’s because we lose control over the TTL when using aliases. If we switch the configuration to CNAMEs, set the TTL to 1s, and pair it with a 10s health check with a single failure threshold-

And run the test again, things should be good, right?

This wasn’t what I was expecting, because in the days of Route53 testing leading up to actually sitting down and writing out the results I had gotten the failover down to 17–24 seconds with a latency policy atop a weighted policy, using 10s health checks. I was prepared to just chalk it up part of using ephemeral, multi-tenant infrastructure is accepting that there will be some measure of variability in performance based on peak usage, behind-the-scenes maintenance, and other factors outside of your control. But that seemed like a cop-out the more I thought on it.
Then I remembered- I was using Application Load Balancers with these tests, and had used Network Load balancers when I saw the lower failover numbers. So let’s replace our ALBs with NLBs, and do the failover test as configured above:

The time to failover improved to 30s for AMERS to EMEA failover, and 25s for EMEA to ASPAC failover. Better, but is there room still for improvement? I reduced the number of health checker regions on the health checks to see if that would reduce the time to fail over at the latency layer.

It did not. So if the regional latency layer is where some of my problems are, maybe I should look into alternative routing strategies, like geolocation.
Geolocation + Nested Failovers
Geolocation allows you to point continent or country traffic to a given DNS alias. As I was already segmented into AMERS, EMEA, and ASPAC, I divided the seven continents plus the default location record set into those regions.
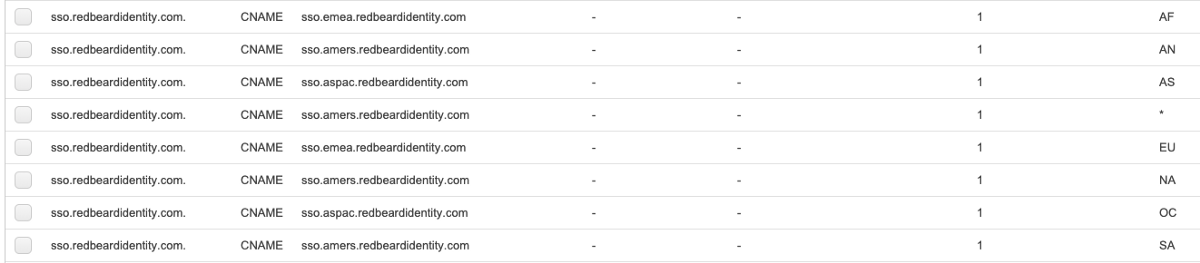
Whereas latency + weighted routing performs failover when a region is lost, I was not certain if the same would happen with geolocation routing. I attached the corresponding health checks for each NLB that would serve each region and ran a test- it would not failover. It looks like in order to use geolocation, we will need to break open the cascading failover routing trees again, giving us something that looks like this:
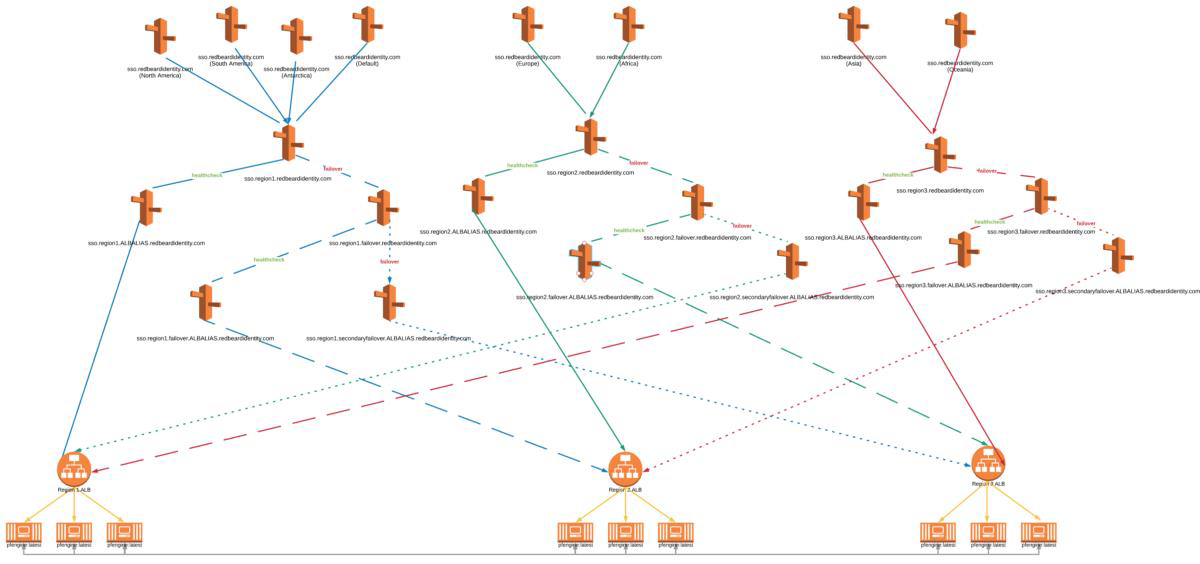
A non-trivial count of Route53 objects later and it is built.
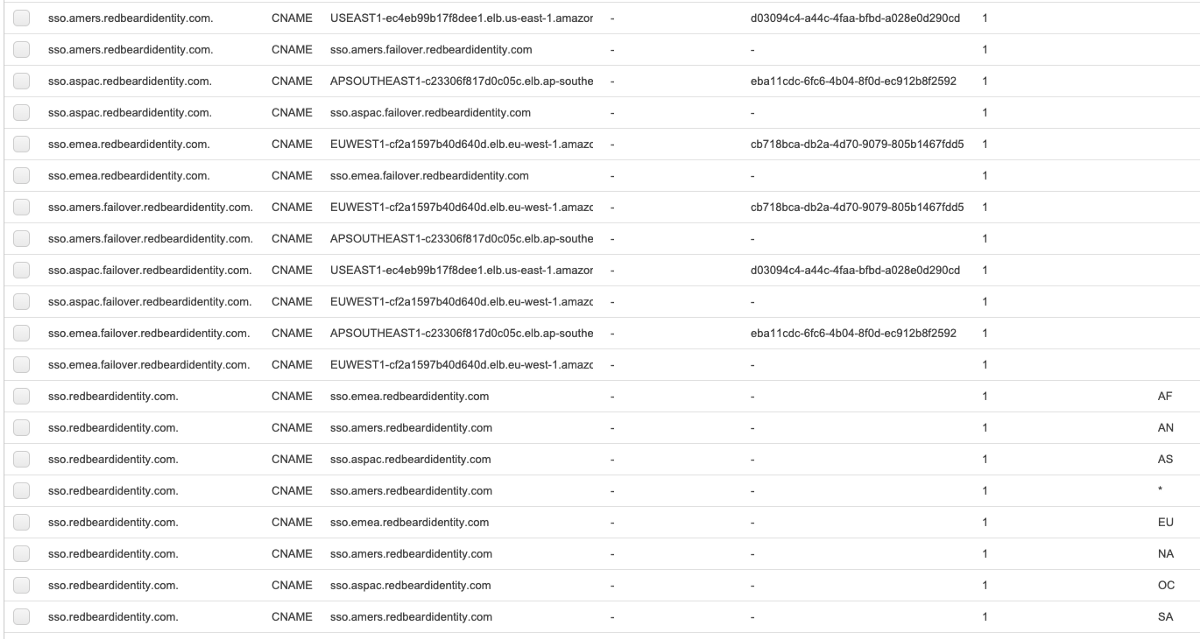
But does it improve anything compared to the simpler arrangements? Using Network Load Balancers, which at this point have proved themselves the go-to if you value performance, I got an AMERS to EMEA failover of 17s and EMEA to ASPAC of 23s.
Whereas these are not the BEST ever numbers I have ever achieved from a battery of tests (there appears to be some variability in the Route53 service), they represent the best consistent failover numbers I have gotten from the tests I ran where all other controls were kept equal. As such, I have to call this one the winner overall.
Additional Thoughts
In all of the designs, the thing that introduces at least 10s of delay every time is waiting for a failed health check. Another design scenario I had considered was using Network Load Balancers pointed to elastic IP addresses which were assigned to other NLBs in peered VPCs. Assuming this were possible, it would let us use the much tighter health check values to add or drop regions much more quickly than what is available in Route53. I abandoned that test because using a NLB in that manner wouldn’t let us keep traffic constrained to a single region, which is one of the goals. Distributing a connection across various regions doesn’t net us any sort of performance benefits from regional sub clustering. So even if I got that arrangement to work, it would short circuit the entire point of the exercise. The limited amount of time I spent poking around the console trying to build something like that leads me to think it‘s not an option, and that if it were then it’s not going to be solved with just the features in EC2 and Route53.
I think this is about as tight as I am getting this through Route53, and given that the scenario under which we would observe those 17–23s of blip during the regional failover is if all the nodes in a given region are down, I suppose I must make peace with that being “good enough.” It isn’t as satisfying a conclusion as I had hoped for, but it was still a fun learning experience.

Jon Lehtinen
Thomson Reuters
Board Member, IDPro

